The research lifecycle
Research is a complex process, and it is most easily understood as a series of steps carried out sequentially in a loop. This loop may repeat one or more times in a project. A commonly-used representation is shown below.
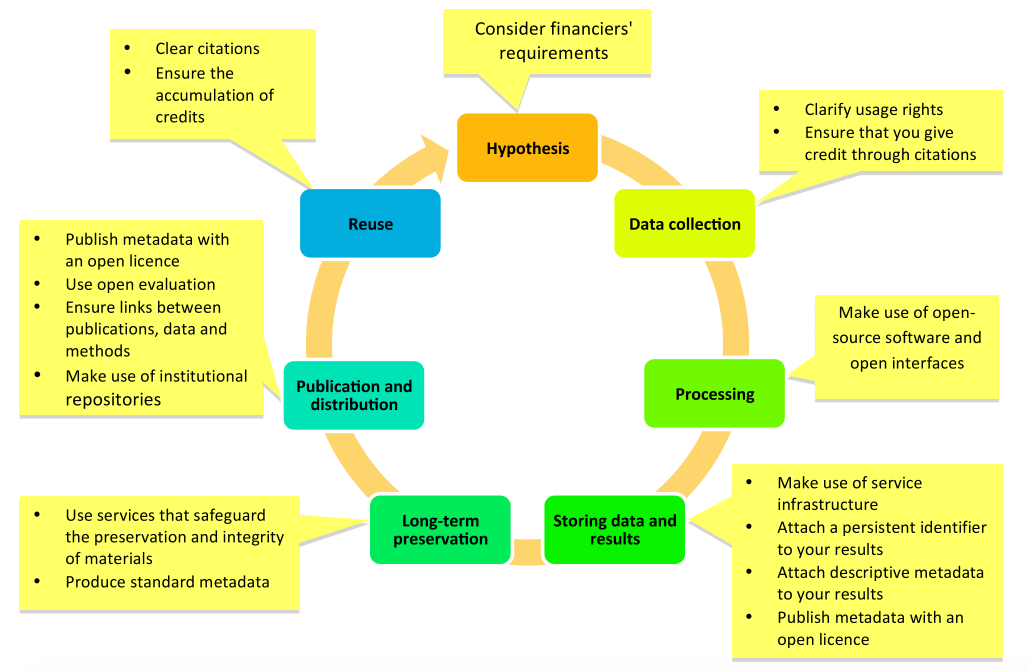 Figure 1. The research lifecyle. From “The Open Science Handbook” (Open Science and Research Initiative, 2014). Used under the Creative Commons Attribution 4.0 International Public License.
Figure 1. The research lifecyle. From “The Open Science Handbook” (Open Science and Research Initiative, 2014). Used under the Creative Commons Attribution 4.0 International Public License.
In reality, some of these phases may run in parallel, for example data collection, processing and storage.
The depicted research lifecycle consists of seven phases:
-
This the cornerstone phase of research. During this phase of the research lifecycle a researcher establishes a research hypothesis (i.e., a problem statement) and selects a research method (e.g., an observational study) which will be used to test/assess the hypothesis.
These steps allow the researcher to further design and plan their research. For example, they might lead to a concept and plans for the experiments or simulation which will be used to test the hypothesis. This in turn allows the researcher to create a Data Management Plan (DMP) which outlines how data will be collected, processed, analyzed, published and preserved. It's worth noting - as pointed out in the graphic - that the funding agency often has a say in the DMP, asking funding recipients to put data in specific repositories or work towards certain goals.
-
In this phase, a researcher puts the DMP into use. They may be collecting data either by acquiring already existing (data re-use) or creating new datasets (act of data creation). Also, during this phase any additional information that could be relevant for data processing is collected or created and organized, such as data reports, experiment log books, existing data processing code, etc. And, as we collect data, we also need to collect the relevant metadata.
-
Then, the collected data are processed to yield information and insights. This phase of the research lifecycle therefore accounts for all of the data processing code.
In experimental studies -- which often have a longer period of time data processing -- the data processing should ideally run in near-real-time with data collection. This helps avoid nasty surprises later in the project when time and resources may be constrained.
It is common that a significant and often unplanned portion of the resources allocated to data processing are actually spent on data preparation (e.g., data wrangling, filtering, quality control, quality assurance, etc.) prior to data processing. According to one study, data preparation typically accounts for 80% of researcher’s time, whereas the remaining 20% of their time is spend on the actual data processing FORBES.
Larger data collections should be annotated) while processing them. This enables the data to be split into subsets for later analysis. This reduces the amount of time spent on data preparation if the data are re-used.
-
This phase actually runs in parallel with data collection and data processing. As we collect and process data, we need to find and allocate storage for metadata, data, data annotations, data processing code and the results of data processing.
During this time the researcher needs temporary, fast access storage services which allow a team of researchers to work jointly on data. These services are often offered by universities. Researchers can also take advantage of European collaborative data infrastructures such as the EUDAT B2Drop service.
-
University policies often guarantee data storage for up to 5 years after the completion of a research project. This can be considered data preservation for the mid-term. Physical tapes and dedicated 'offline' data warehouses are typically used for long-term data preservation (5+ years). Data in long-term preservation are safely stored and protected from outside influence, but accessible on demand.
-
Researchers usually generate many outputs during the research process. These may occur before or after a traditional scientific paper, and may include data, data processing code, and data annotations. These outputs are still publishable and should be published, as they have value for colleagues and the wider community.
For each research output, the researcher can either publish only the output's metadata, or the output with metadata. This has several reasons: 1. metadata will live longer than data, 2. although you want to announce that you created dataset, you still want to be the first one who has access to it (you could put an embargo, but often because of (1) you want to detach metadata and data or at least to have a sole copy of metadata published without data), 3. You might have data that you cannot share with everyone, but still want to report that you have it and to cite it (i.e., you want unique and persistent identifier of metada).
When publishing, a researcher must select an appropriate license which clarifies the terms of usage of the published asset. The type of license will depend on the asset.
- Metadata, data, and data annotations typically use Creative Commons licenses.
- Data processing code can use various licenses, where MIT or BSD are among favorites in the open source community.
A researcher needs to assign a persistent identifier (PID) to every output. This allows efficient citation. A Digital Object Identifier (DOI) is typically used as the PID for metadata, data, and data annotations, and data processing code.
Published outputs can be protected temporarily through an embargo. The embargo is a period during which access to the published output is limited to the output's author(s). However, the metadata are accessible, and thus the output can be cited. This may be particularly helpful for datasets.
The resulting scientific paper(s) can then cite all of these other products. In this way scientific papers will contain a full chain of custody depicting the entire research lifecycle. Unlike a scientific paper, who's content cannot be edited once it has been published, the metadata of other research outputs can be edited to point back to the scientific papers which make use of them. This allows the creation of a network of citation and increased professional recognition.
-
If the previous phases are done well, the outputs generated in each turn of the research lifecycle will be used again, beyond the project lifetime. This brings higher impact from research, often measured through an increased number of citations.
Roles in lifecycle
There are usually many people involved in the research lifecycle, and they each play different roles. Unfortunately these people are not always visible in traditional papers, despite their important contributions.
The CRediT taxonomy identifies 14 roles based on their contribution to each research output:
- Conceptualization – Ideas: formulation or evolution of overarching research goals and aims (see Hypothesis phase).
- Data curation: Management activities to annotate (produce metadata), scrub data and maintain research data (including software code, where it is necessary for interpreting the data itself) for initial use and later re-use (see Data collection, Processing and Storage).
- Formal analysis: Application of statistical, mathematical, computational, or other formal techniques to analyze or synthesize study data (see Processing).
- Funding acquisition: Acquisition of the financial support for the project leading to this publication (see Hypothesis phase).
- Investigation: Conducting a research and investigation process, specifically performing the experiments, or data/evidence collection (conducting entire research lifecycle).
- Methodology: Development or design of methodology; creation of models (see Hypothesis phase, especially DMP).
- Project administration: Management and coordination responsibility for the research activity planning and execution.
- Resources: Provision of study materials, reagents, materials, patients, laboratory samples, animals, instrumentation, data, computing resources, or other analysis tools (see Data collection).
- Software: Programming, software development; designing computer programs; implementation of the computer code and supporting algorithms; testing of existing code components (see Processing).
- Supervision: Oversight and leadership responsibility for the research activity planning and execution, including mentorship external to the core team (all phases of the research lifecycle).
- Validation: Verification, whether as a part of the activity or separate, of the overall replication/reproducibility of results/experiments and other research outputs.
- Visualization: Preparation, creation and/or presentation of the published work, specifically visualization/data presentation (see Data processing, Storage and Publishing).
- Writing – original draft: Preparation, creation and/or presentation of the published work, specifically writing the initial draft (see Publishing).
- Writing – review & editing: Preparation, creation and/or presentation of the published work by those from the original research group, specifically critical review, commentary or revision including pre- or post-publication stages (see Publishing).
 Figure 2. CRediT roles identify the contribution of different actors to a research output. They are depicted here as OpenBadges (source: Github)
Figure 2. CRediT roles identify the contribution of different actors to a research output. They are depicted here as OpenBadges (source: Github)
We suggest that every contributor to each research output should be assigned one of these roles. This should be done in the output metadata and where possible in the output itself. In case of scientific papers, the dedicated section Author Contributions should contain explicitly stated contribution of each author.
The following example shows an Author Contributions section from a Cell Press paper as well as a version that has been re-written to include the CRediT taxonomy.
Original: S.C.P. and S.Y.W. conceived and performed experiments, wrote the manuscript, and secured funding. M.E., A.N.V., and N.A.V. performed experiments. M.E.V and C.K.B. provided reagents. A.B., N.L.W., and A.A.D. provided expertise and feedback.
CRediT revised: Conceptualization,S.C.P. and S.Y.W.;Methodology, A.B., S.C.P.,and S.Y.W.; Investigation, M.E., A.N.V., N.A.V., S.C.P., and S.Y.W.; Writing – Original Draft, S.C.P. and S.Y.W.; Writing – Review & Editing,S.C.P. and S.Y.W.; Funding Acquisition, S.C.P. and S.Y.W.; Resources,M.E.V and C.K.B.; Supervision, A.B., N.L.W., and A.A.D